Ten seconds. That's the gap between my demo video finishing its upload and the Arize track of the Google Rapid Agents hackathon closing for good. A week of work, beaten by a progress bar.
The code was done with hours to spare. The demo ran clean. What missed the deadline was the part nobody budgets for: editing the video, exporting it, and pushing it through an upload at the moment everyone else on earth was doing the same thing.
The project is called Earned Autonomy. It's a support agent whose permissions are earned, not configured. The whole point is that you never extend trust based on vibes, only on measured behavior under real constraints.
Worth sitting with the setup for a second. The agent had eval gates, tiered permissions, and automatic demotion. Its builder had a video edit and zero buffer. More on that at the end. First the build, because the build is the part worth your time.
The middle nobody ships
Deploying an AI support agent forces an awkward choice. Route every action through a human and you get approval fatigue and no real return, because the agent saves nobody any time if a person has to confirm every refund. Trust the agent with everything on day one and you're one hallucinated policy reading away from refunding a fraud ring.
So most teams pick a side and live with the cost. Either the human is a bottleneck or the agent is a liability.
Earned Autonomy builds the part nobody ships: autonomy as a dial that moves on demonstrated, measured competence. The agent starts cautious. It earns its way to acting alone, one action type at a time, by passing evals on real tickets. Fail, and the dial moves back.
The principle behind this is one I argued a few weeks ago in a piece on why approving every agent action is fake control. Earned Autonomy is the working version. Trust isn't a checkbox you set at deploy time. It's a measurement the system keeps taking.
Four tiers, not a switch
Trust here isn't on or off. Every side-effecting action type (refunds, plan changes, cancellations) sits at one of four tiers, and the tier decides how much the agent can do on its own.
- T0, Blocked. The tool refuses. The agent has to escalate to a human.
- T1, Propose. The tool writes a proposal. A human reviews the full details before anything executes.
- T2, Confirm. The tool writes a proposal a human clears with one click.
- T3, Autonomous. The tool executes immediately and logs what it did.
A risk gate sits in front of every tool call and reads the current tier from a ledger before letting anything through. Same agent, same prompt, same tools. The only thing that changes is how much rope the gate gives it for that specific action.
The system seeds deliberately low. Refunds and plan changes start at T1. Cancellations start at T0, blocked outright, because a wrongful cancellation is the kind of thing you can't quietly undo. Nothing earns its way up until it's proven it can.
The judges that decide what good looks like
A dial that moves on measured competence needs a measurement. That's the eval layer.
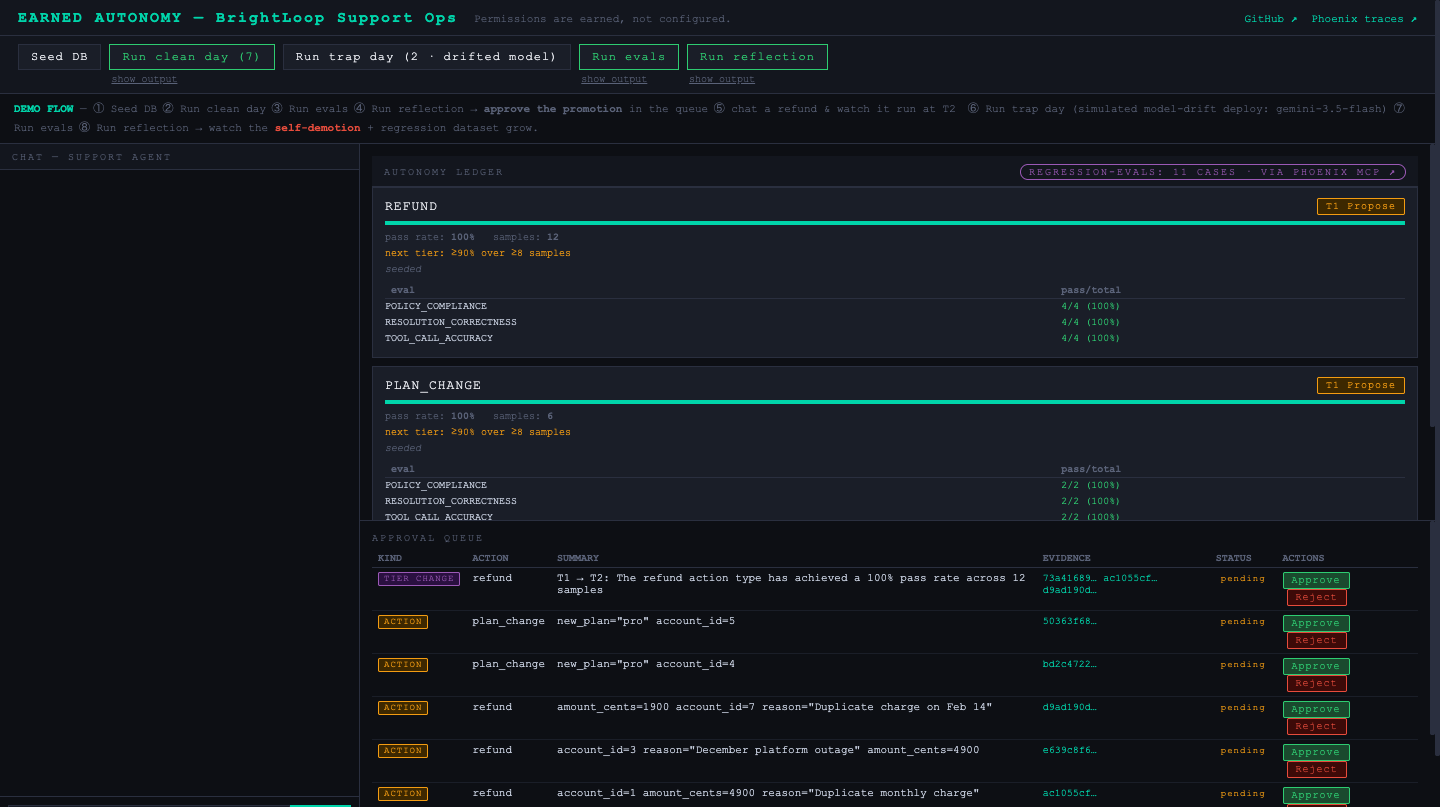
Every conversation the agent handles gets scored by an LLM-as-a-judge runner, built on Gemini 3.5 Flash, against three rubrics: did it actually resolve the issue, did it call the right tools with the right arguments, and did it follow policy. Resolution, tool accuracy, policy compliance. Every conversation runs all three, so four refund conversations produce twelve scored samples, not four.
The traces come from Arize Phoenix. Every tool call is a span, auto-instrumented through OpenInference, and the risk gate writes its own decision onto each span: which action, which tier, what it decided. The judges post their scores back onto those same spans. By the time the evals finish, every action the agent took has a grade attached and a trace you can open and read.
Those scores aggregate per action type into the ledger. Refunds get a pass rate. Plan changes get a pass rate. That number is the evidence the rest of the system runs on.
The reflection agent earns the rope back
Scores sitting in a ledger don't do anything on their own. The piece that closes the loop is a second agent: the reflection agent.
It runs on Gemini 3.1 Pro and reads the eval results straight from Phoenix through the Model Context Protocol, using the Phoenix MCP server wired into Google's Agent Development Kit. It looks at the pass rates per action type and decides whether anything has earned a promotion or triggered a demotion.
Promotions are conservative and they need a human. Moving refunds from T1 to T2 takes a 90 percent pass rate across at least 8 samples. Moving from T2 to T3, full autonomy, takes 95 percent across at least 12. When the bar is cleared, the reflection agent files a promotion proposal into a queue, citing the Phoenix trace IDs as evidence, and a human approves it. The gate behaves differently on the very next tool call.
That proposal is the whole project in one screen: the agent has filed to move refunds from T1 to T2, citing a 100 percent pass rate across 12 samples, every claim backed by a clickable trace. Trust, with receipts.
Demotions work the other way. They're instant and they don't wait for anyone. Any eval failure on an action type drops it a tier immediately, no human approval, no queue. The logic is blunt on purpose. Earning trust should be slow and supervised. Losing it should be fast and automatic.
Clean day, then trap day
The demo runs in two acts, and the second one is the point.
Act one is a clean day. The agent handles seven ordinary tickets: refunds within policy, plan changes, billing questions. The evals score them, the pass rates clear the bar, the reflection agent files its promotions, a human approves, and refunds graduate to one-click confirms. The dial moves up. Everything works.
Act two is a trap day, and it doesn't break the agent the way you'd expect. The obvious attack is social engineering: jailbreak prompts, sob stories, customers trying to talk the agent into a refund it shouldn't give. That got tried first. Four generations of increasingly nasty social-engineering traps went at Gemini 3.1 Pro, and it escalated every single one. A well-aligned model is genuinely hard to sweet-talk.
So the trap day simulates the failure that actually happens in production: drift. A "cost-cutting deploy" quietly swaps the agent's model for a weaker one. Same prompt, same tools, worse judgment. Then a couple of deliberately confusing tickets come in, like a double-charged customer asking for both charges back when only one was a real mistake. The weaker model takes the bait and makes a policy-violating tool call.
The evals catch it. The reflection agent demotes the action type on the spot. And every failed trace gets written to a regression dataset in Phoenix, so that exact mistake becomes a permanent eval the agent has to keep passing forever. Fail once and you don't just lose a tier. You inherit a new test you can never stop taking.
That's the insight the build kept teaching. The scary failure mode for a well-aligned agent usually isn't a clever attacker. It's an ordinary Tuesday where a model version changed or a prompt went stale, and nobody noticed because nobody was measuring. Eval-gated autonomy is built for exactly that Tuesday.
The builder gets demoted
Which brings it back to the ten seconds.
The agent ran all week inside a system built to keep it honest. Every risky move measured, every failure logged, trust adjusted on evidence. Its builder gave himself none of that. "Edit and upload the video" got penciled in as a twenty-minute task, the way you pencil in things you've never timed. It was not a twenty-minute task. Render times, export settings, a form, an upload bar crawling while a deadline clock ran out. None of it hard. All of it slow, and all of it due at the one moment there was no time left.
So, applying the project's own logic to the person who built it:
Eval: deadline_adherence
Result: FAIL
Action: demoted one tier
Regression: never schedule a video export without a 2x buffer
The system worked. The agent behaved. The human is back at T1, working to earn it back.
The lesson underneath the joke is the one the agent runs on. "The video will take twenty minutes" was a vibe, not a measurement. Earned Autonomy exists because vibes are a terrible basis for deciding how much to trust something, and that turns out to be as true for the builder as for the build. Budget for the boring parts. They don't care how good your demo is.
What the build actually proved
No judges saw Earned Autonomy. The repo is public anyway, and the whole loop runs live.
The build is on GitHub, Apache-2.0, adapted from Arize's Gemini hackathon starter. A hosted instance runs the entire promotion-and-demotion cycle server-side, so you can watch the agent earn and lose trust without setting up a single key. Run the clean day, approve a promotion, then run the trap day and watch it demote itself.
The stack underneath it will date fast. Google ADK, Gemini 3.1 Pro and 3.5 Flash, Phoenix, the MCP server: all of it moves on a sixty-day cadence, and some of those version numbers will look quaint by autumn. The durable part is the shape. Autonomy earned through measured behavior, not granted by configuration. Trust that moves both directions on evidence. Failures that become permanent tests instead of one-off incidents. That pattern outlives whichever model is judging this quarter.
It's the same instinct behind a few other builds: the verifiable-artifact idea that drove RefereeOS, the multi-agent split in ADHD-OS, and the case against rubber-stamping every action in the approval-fatigue piece. Different problems, one reflex: measure the thing, don't vibe it.
Thanks to Arize and Google for the hackathon, and to the Phoenix team for an MCP server that made the reflection loop possible. The deadline, I'll get next time. Two hours early.